Google svela come far cooperare i sistemi AI multi-agente
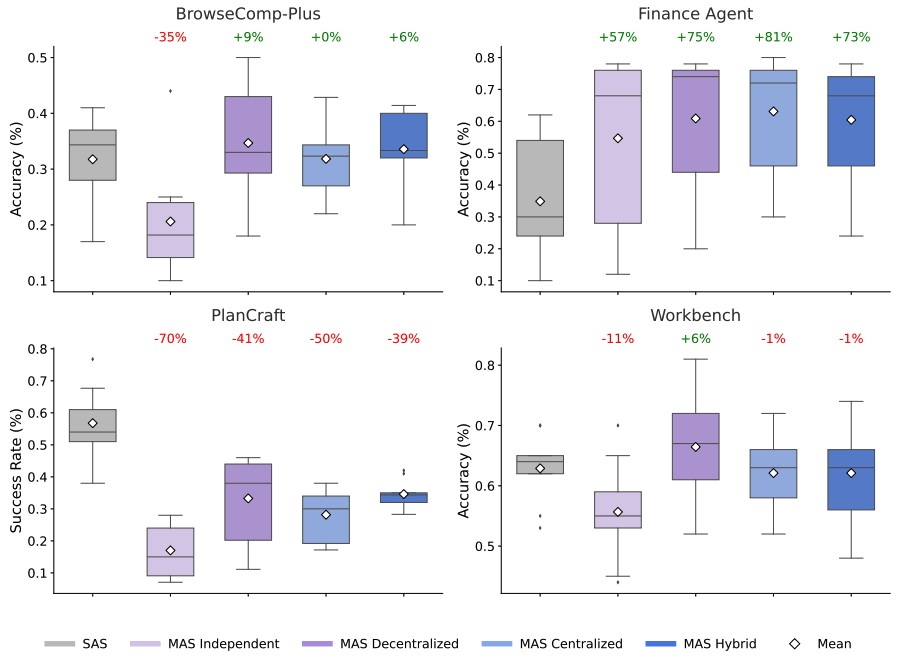
Una scoperta rivoluzionaria arriva dai laboratori di Google che potrebbe cambiare per sempre il modo in cui concepiamo l’intelligenza artificiale collaborativa. Il team Paradigms of Intelligence di Big G ha dimostrato che per creare sistemi AI cooperativi non servono complesse regole hardcoded: basta allenare gli agenti contro avversari imprevedibili e diversificati.
La ricerca, che sfida i paradigmi attuali dello sviluppo AI, mostra come un approccio più naturale e scalabile possa risolvere uno dei problemi più spinosi dell’intelligenza artificiale moderna: far collaborare multiple AI senza che si sabotino a vicenda. Una questione tutt’altro che teorica, considerando che il futuro tecnologico si sta rapidamente orientando verso ecosistemi di agenti AI interconnessi.
I risultati potrebbero rivoluzionare settori chiave come la fintech, la logistica e l’automazione industriale, dove la coordinazione tra sistemi autonomi rappresenta spesso il collo di bottiglia principale per l’innovazione.
Il paradosso della cooperazione artificiale
Il panorama dell’intelligenza artificiale sta vivendo una trasformazione epocale: si sta passando da sistemi isolati a flotte di agenti che devono negoziare, collaborare e operare simultaneamente in spazi condivisi. Tuttavia, questa evoluzione porta con sé una sfida fondamentale che i ricercatori chiamano “mutual defection”, ispirandosi al famoso Dilemma del Prigioniero della teoria dei giochi.
Il problema nasce dal fatto che ogni agente AI è progettato per massimizzare le proprie metriche specifiche, spesso entrando in conflitto con gli obiettivi degli altri. Immaginate due algoritmi di pricing automatizzato che si sfidano in una gara al ribasso distruttiva: ognuno ottimizza per il proprio tornaconto, ma il risultato finale danneggia l’intero sistema aziendale. È esattamente questo tipo di stallo che Google ha deciso di affrontare con un approccio completamente nuovo.
Alexander Meulemans, co-autore della ricerca e Senior Research Scientist del team Paradigms of Intelligence, spiega la limitazione degli approcci tradizionali: “Il limite principale dell’orchestrazione hardcoded è la sua mancanza di flessibilità. Mentre le state machine rigide funzionano adeguatamente in domini ristretti, non riescono a scalare quando la portata e la complessità delle implementazioni si amplia”.
La rivoluzione del machine learning decentralizzato
La soluzione proposta da Google ribalta completamente il paradigma attuale. Invece di definire regole esplicite di coordinazione, il nuovo metodo allena gli agenti LLM attraverso reinforcement learning decentralizzato contro un pool misto di avversari: alcuni attivamente in apprendimento, altri statici e basati su regole predefinite. L’agente impara a leggere ogni interazione e ad adattare il proprio comportamento in tempo reale attraverso in-context learning.
Questa tecnica si basa su un nuovo metodo chiamato Predictive Policy Improvement (PPI), che secondo Meulemans è model-agnostic e può essere implementato con algoritmi di reinforcement learning standard come GRPO. “Piuttosto che allenare un piccolo set di agenti con ruoli fissi, i team dovrebbero implementare una routine di allenamento ‘mixed pool’”, consiglia il ricercatore.
L’approccio espone gli agenti a interazioni con co-player diversificati, variando nei system prompt, nei parametri fine-tuned o nelle policy sottostanti. Questo crea un ambiente di apprendimento robusto che produce strategie resilienti quando si interagisce con nuovi partner, garantendo che l’apprendimento multi-agente sia davvero scalabile.
Impatto sui framework di sviluppo attuali
La ricerca di Google ha implicazioni dirette per gli sviluppatori che utilizzano framework come LangGraph, CrewAI o AutoGen. Questi strumenti richiedono attualmente di definire esplicitamente agenti, transizioni di stato e logica di routing come un grafo. LangChain descrive questo approccio come equivalente a una state machine, dove i nodi degli agenti e le loro connessioni rappresentano stati e matrici di transizione.
Il modello di Google inverte questa logica: invece di hardcodare come gli agenti dovrebbero coordinarsi, produce comportamenti cooperativi attraverso l’allenamento, lasciando che gli agenti inferiscano le regole di coordinazione dal contesto. Questo rappresenta un cambio di paradigma che potrebbe semplificare drasticamente lo sviluppo di sistemi multi-agente complessi.
Per il mercato italiano, questa innovazione potrebbe tradursi in opportunità concrete per settori ad alta intensità tecnologica. Le aziende fintech, i provider di servizi cloud e le industrie 4.0 potrebbero beneficiare di sistemi AI più flessibili e scalabili, riducendo i costi di sviluppo e manutenzione dei sistemi di automazione complessi.
Prospettive future e applicazioni concrete
La scoperta di Google apre scenari affascinanti per il futuro dell’AI enterprise. Sistemi di trading automatizzato che collaborano invece di competere distruttivamente, reti logistiche che si auto-ottimizzano in tempo reale, o ecosistemi di customer service dove chatbot specializzati si coordinano seamlessly per risolvere query complesse.
La chiave del successo risiede nella capacità di creare ambienti di training diversificati che preparino gli agenti a scenari imprevisti. Questo approccio non solo risolve il problema della scalabilità, ma introduce anche un elemento di robustezza che i sistemi hardcoded tradizionali non possono offrire.
Mentre aspettiamo implementazioni concrete di questa tecnologia, una cosa è certa: Google ha dimostrato che la cooperazione artificiale può emergere naturalmente da condizioni di allenamento appropriate, aprendo la strada a una nuova generazione di sistemi AI veramente collaborativi. Il futuro dell’intelligenza artificiale sembra sempre più orientato verso ecosistemi dove la competizione lascia spazio alla sinergia, proprio come accade nei migliori team umani.
Fonte: VentureBeat





